
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 마크다운
- khaiii
- Technical Writing
- 코딩온라인
- 파이콘
- Kakao
- address
- 플젝후체크
- Anaconda
- taskkill
- 출처: 자바의 신 8장
- 클라이언트사이드렌더링
- Machine Learning
- 필사
- 서버사이드렌더링
- 카우치코딩 #couchcoding #6주포트폴리오 #6주협업프로젝트v
- Morphological analysis #Corpus
- SSR
- terminate
- PID
- 자바파이썬
- gitbash
- #스파르타코딩클럽후기 #내일배움캠프후기
- 파이썬
- expression statement is not assignment or call html
- github
- 비동기
- 카우치코딩 #couchcoding #6주포트폴리오 #6주협업프로젝트
- github markdown
- 모바일웹스킨
- Today
- Total
개발 일기
Khaiii Github - CNN Model 본문
CNN (Convolutional Neural Network) Model
Khaiii used the CNN Model as an algorithm for machine learning.
Syllable-Based model
When it comes to morphological analysis of Korean, the analysis result often displays a different form and length than the input due to syllable restoration, irregular eogan (parts of word like ‘빌’ of ‘빌리다’) and eomi (parts of word that may change like ‘리다’, ‘렸다’ of ‘빌리다’ to express different tense/meaning, etc). For example, the analysis result of 져줄래 is 지/VV + 어/EC + 주/VX + ㄹ래/EF, which shows that it is hard to predict both the length and form of the input’s analysis result. Due to the difference in length, it’s important to use a machine learning classifier and to design how the model will print the results.
For the classic HMM and CRF models, they used a TRIE Dictionary and Viterbi algorithm to find the best route for going through uneven lattice grids.
In the latest deep learning method, the sequence- to- sequence model (seq2seq) is frequently used in translation. We would use an encoder and create latent vectors for the input 져, 줄, 래, and use a decoder and print 지/VV, 어/EC, 주/VX, ㄹ래/EF. We can apply the attention mechanism as well. However, the Recurrent Neural Network model (RNN) which is frequently used in seq2seq is slow. With the RNN method, when the input syllable is morphologically analyzed, there will be missing information that explains which analysis result comes from which part of its input.
Therefore, Khaiii prints one output tag per syllable.
The Mechanisms Behind the Arrangement of syllables and Morphemes
Khaiii classifies each input syllable rather than each word. After the first morphological analysis, there will be further processing by taking each morpheme and attaching a tag to each syllable (in the IOB1 format) as seen below [Tjong Kim Sang 1999]
입력(Input): 심사숙고했겠지만
분석(Morpheme analysis): 심사/NNG + 숙고/NNG + 하/VX + 였/EP + 겠/EP + 지만/EC
태그(Tags): 심/I-NNG, 사/I-NNG, 숙/B-NNG, 고/I-NNG, 하/I-VX, 였/I-EP, 겠/B-EP, 지/I-EC, 만/I-ECAs a result of such arrangements, each syllable will be viewed as seen below.
| Input Syllable | Analysis result | Output tag |
|---|---|---|
| 심 | 심/I-NNG | I-NNG |
| 사 | 사/I-NNG | I-NNG |
| 숙 | 숙/B-NNG | B-NNG |
| 고 | 고/I-NNG | I-NNG |
| 했 | 하/I-VX, 였/I-EP | I-VX:I-EP:0 |
| 겠 | 겠/B-EP | B-EP |
| 지 | 지/I-EC | I-EC |
| 만 | 만/I-EC | I-EC |
While 했 has a complex (multiple) tag of I-VX:I-EP:0, other syllables have simple (single) tags. The difference between complex tag and simple tag relates to whether it uses the syllable restoration dictionary. The 했/I-VX:I-EP:0 key is a combination of both a syllable and a complex tag. If you search the dictionary using this key, you will get the restored information classified as 하/I-VX, 였/I-EP.
Khaiii processes morphemes and assigns a tag to each syllable. Then, restores its origin from tags. Khaiii team came up with this idea from the professor Sim Gwang Seob’s thesis [reference: Sim Gwang Seob 2013].
Every syllable within the corpus can be arranged with its morphological analysis results. If necessary, one can also create a complex tag in sequences such as I-VX:I-EP:1, I-VX:I-EP:2, and automatically create the syllable restoration dictionary. Below is one of the examples of training data.
프랑스의 I-NNP I-NNP I-NNP I-JKG
세계적인 I-NNG I-NNG I-XSN I-VCP:I-ETM:0
의상 I-NNG I-NNG
디자이너 I-NNG I-NNG I-NNG I-NNG
엠마누엘 I-NNP I-NNP I-NNP I-NNP
웅가로가 I-NNP I-NNP I-NNP I-JKS
실내 I-NNG I-NNG
장식용 I-NNG I-NNG I-XSN
직물 I-NNG I-NNG
디자이너로 I-NNG I-NNG I-NNG I-NNG I-JKB
나섰다. I-VV I-VV:I-EP:0 I-EF I-SFAt the same time, Khaiii automatically creates the syllable restoration dictionary as seen below.
인/I-VCP:I-ETM:0 이/I-VCP ㄴ/I-ETM
섰/I-VV:I-EP:0 서/I-VV 었/I-EPOnce you finish arranging every word within the corpus, 92 fixed simple tags and about 400 complex tags will be created. In order to automate arrangement, we designed it to utilize manually written rules and mapping dictionaries. We excluded the sentences that failed to be arranged from learning. Now you will have about 500 output tags to classify each input syllable.
Windows and Syllable Context
In order to classify a tag for a syllable, we read the windows to left and right of the syllable. For example, below is an input called 프랑스의 세계적인 의상 디자이너 엠마누엘 … This syllable context has 7 window sizes and classifies tags for the syllable 세 as follows.

When khaiii reads the syllable context, it uses virtual syllables which are a different types of syllables than those mentioned so far as seen below.
| Virtual syllables | Meaning |
|---|---|
| Out of Vocabulary syllable | |
| Left word boundary (Space) | |
| Right word boundary (Space) | |
| zero vector padding |
The left word boundaries are in order of '프', '세', '의', '디', '엠', ... The right word boundaries are in order of '의', '인', '너', '~엘', ... Khaiii does not use every word boundary, but only the closest one to the right and left. In the above example, ‘세’ is the left border and ‘인’ is the right border.
When we add word boundaries to the learning process, we apply a certain percentage of drop-out. By doing so, we can add a noise data such as spacinge errors (where there lacks a necessary space). Khaiii does not change the user’s input in the inference process. These help prevent over-fitting, like applying drop-out between layers, and encourage the model to learn a way to better recognize spacing errors.
Network Structure

Convolution: CNN (Convolution Neural Network) consists of a convolution and a pooling layer. The term convolution refers to the mathematical combination of two functions to produce a third function. Pooling is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network.
In the left of the diagram, you can see the convolution* operation which uses a window size of 7, syllable embedding size of 5, 4 filters with cunnel size of 3. If a window whose size is [15,5] goes through one of the filters, a vector with a length of 13 will be created. If you apply max pooling to the entire filters, it will be a scalar value. Having used four filters, this will result in a vector length of 4.
For those cunnel sizes of {2,3,4,5} , we will connect its vectors (each has a length of 4) and create a vector with a length of 16. After going through a hidden layer and a printing layer, the tag will be confirmed.
In fact, a base model has a window size of 4 and embedding size of 35. For the filter’s printing dimension, we have used 35, the same as the embedding size. After going through four different types of cunnels {2,3,4,5}, a vector with a length of 140 will be created. The number of final printing tags is 500 and the dimension of the hidden layer is 320, the average of 140 and 500.
This convolution method referenced Yoon Kim’s thesis on sentence classification (We have referred this convolution method to Yoon Kim’s thesis on sentence classification) His thesis uses words to classify sentences, whereas Khaiii utilizes syllables to analyze the syllable context.
Multi-Task Learning
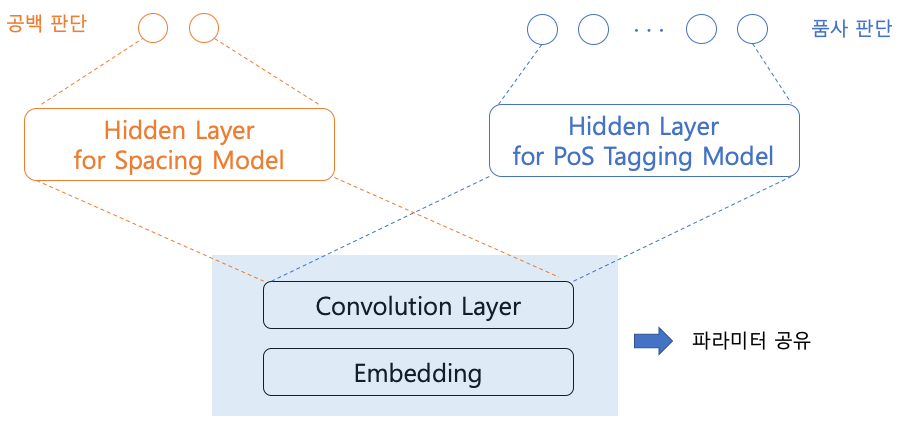
The Khaiii team used an existing model which evaluates a part of speech by each syllable, and a new model which evaluates whether each syllable should be spaced. We applied multi-task learning to both models. Embedding and convolution layers share parameters. Each of the downstream tasks is a hidden layer. We separated these layers and trained them. In this case, inference does not require any changes to be made.
Reference: Test for Specialized Spacing Error Model
References
- [Tjong Kim Sang 1999] Representing Text Chunks
- [심광섭 2013] 음절 단위의 한국어 품사 태깅에서 원형 복원
- [Yoon Kim 2014] Convolutional Neural Networks for Sentence Classification
*You can find translator's notes italicized
*The original document can be found https://github.com/kakao/khaiii .Please note that this document has not been reviewed by the Kakao team and it's just my personal project. Please feel free to provide feedbacks on any error that may occur during the translation process.
Translator's Note
Introduce Khaiii Github Translation Project: Link
[Khaiii GIthub] Key terms & Concepts: Link
Other Khaiii Translation
[Khaiii Github] Read Me.md: Link
[Khaiii Github] Pre Analysis Dictionary: Link
[Khaiii Github] CNN Model: Link
[Khaiii Github] Test for Specialized Spacing Error Model: Link
[Khaiii Github] CNN Model Training Process: Link
[Khaiii Github]: Analysis Error Patch: Link
'Technical Writing > Khaiii Wiki Translation' 카테고리의 다른 글
| Khaiii Github - Analysis Error Patch (0) | 2021.07.16 |
|---|---|
| Khaiii Github - CNN Model Training Process (0) | 2021.07.14 |
| Khaiii Github - Test for Specialized Spacing Error Model (0) | 2021.07.12 |
| Khaiii Github - Key terms & Concepts (0) | 2021.07.12 |
| Khaiii Github - Pre Analysis Dictionary (Translated in Eng) (0) | 2021.06.24 |