
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 카우치코딩 #couchcoding #6주포트폴리오 #6주협업프로젝트v
- PID
- 서버사이드렌더링
- 코딩온라인
- 자바파이썬
- Technical Writing
- 파이콘
- 파이썬
- 출처: 자바의 신 8장
- 플젝후체크
- terminate
- github
- Anaconda
- 필사
- Machine Learning
- gitbash
- #스파르타코딩클럽후기 #내일배움캠프후기
- 모바일웹스킨
- SSR
- expression statement is not assignment or call html
- taskkill
- khaiii
- 카우치코딩 #couchcoding #6주포트폴리오 #6주협업프로젝트
- Kakao
- github markdown
- 클라이언트사이드렌더링
- 비동기
- address
- Morphological analysis #Corpus
- 마크다운
- Today
- Total
개발 일기
Khaiii Github - Test for Specialized Spacing Error Model 본문
Khaiii Github - Test for Specialized Spacing Error Model
flow123 2021. 7. 12. 14:28Test for Specialized Spacing Error Model.**
Overfitting: If a model is overfitted, it would have a high accuracy to the training data, but it does not work properly on the verification or test data. An overfitted model struggles to evaluate new data. This means the model has been adapted too closely to the training data and even learned its noise.
A user often forgets to put a space (especially on mobile devices) where it’s supposed to. Khaiii was trained by the Sejong Corpus which does not have spacing error data and it became vulnerable to spacing errors. As you see in the CNN Model, in order to perform an analysis based on syllables, Khaiii creates context as the size of the windows and adds the virtual syllables “
Spacing Dropout Test
Decoder: unfolds a vector representing the sequence state and return something meaningful for us like text, tags, etc. Baeldung.com
The Khaiii team chose the Dropout algorithm to train neural networks. When adding the virtual syllables “
Test Result
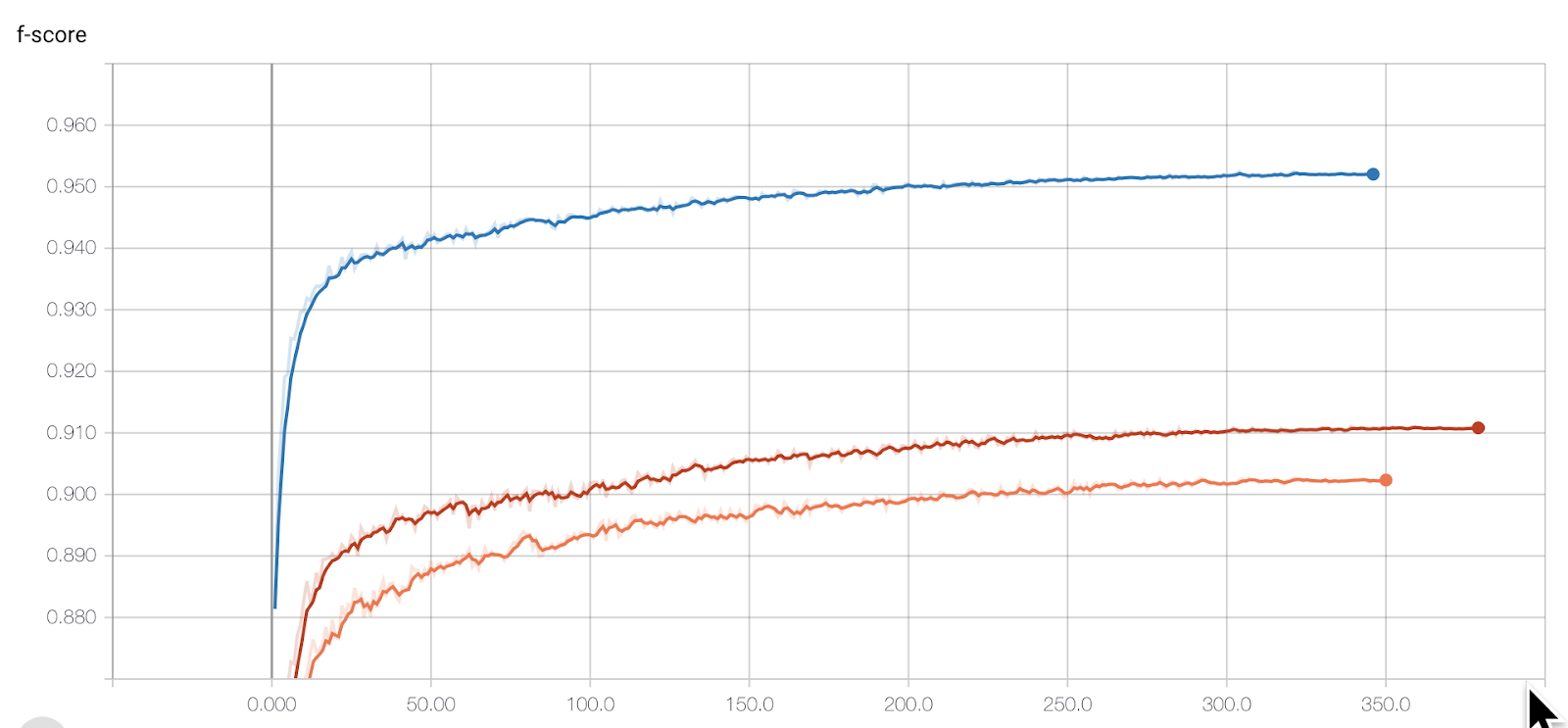
Blue: v0.3 model (dropout 0.0)
Red: Spacing was not added (dropout 1.0)
Orange: spacing drop out (seldomly selected neurons ignored) (dropout 0.5)
The Sejong Corpus has accurate spacing, it’s apparent that the v0.3 model has the best performance as it was trained by the Corpus. However, when compared with other models, the orange model (dropout 0.5) exhibits lower performance than the red one (dropout 1.0), which does not have any spacing at all.
We can assume that there are several factors that may explain the orange model’s low performance. In the orange model, when randomly adding the virtual syllables (spacing), there would probably be changes made in the syllable’s position encoding information, which could cause the input to the convolution filter to become uneven.
Element-Wise Sum Operation Model
Element-wise: a binary operation that takes two matrices of the same dimensions and produces another matrix of the same dimension as the operands
Embedding: a relatively low-dimensional space into which you can translate high-dimensional vectors
Padding: the amount of pixels added to an image when it is being processed by the kernel of a CNN.
Masking: a way to tell sequence-processing layers that certain timesteps in an input are missing, and thus should be skipped when processing the data.
Resources: Wikipedia, Google Developers, Google Colaboratory, kdnuggets.com,
In the v0.3 model, spacing syllables are positioned in the syllable context and they are treated just like any other syllable. In the new model, at the position of the word's left/right border, we will do the element wise sum for “
Changes below have been made for this test.
- The v0.3 model allows for left and right paddings,
andvirtual syllables, to be embedded. In the new version, we’ve changed the setting so that this padding has zero embeddings and can be skipped. The positional encoding still covers this padding, and we have not fully masked them. - For spaces, we have used a
at the left of the word and a at the right, and added them through an element-wise operation.
Test Result

- Blue: dropout=0
- Pink > brown > green: dropout each 0.25, 0.5, 0.75
- Baby blue: this model does not use spacing syllables. dropout = 1.0
For the v0.3 model, spacing syllables have their positions like other syllables, and the drop out = 0.5 model has the lowest performance. For the element-wise models, the drop out = 1.0 model has the lowest performance.
In this model, the accuracy (F-score) gradually decreases as the drop out ratio increases.
The dropout = 0.5 model has 1%p lower performance than the blue one (drop out = 0). The dropout = 0.25 model has only 0.5%p difference compared to the drop out = 0 model, which seems appropriate.
The Khaiii team decided to perform a multi-task test before choosing the model.
Spacing Model & Multi-Task learning
Fully- connected layers : *Fully Connected layers in neural networks are those layers where all the inputs from one layer are connected to every activation unit of the next layer. In most popular machine learning models, the last few layers are full connected layers which compile the data extracted by previous layers to form the final output (https://iq.opengenus.org/).
A v0.3 model evaluates appropriate POS tags, but it’s not specialized for spacing, while the specialized for spacing model cannot classify POSs. Hence, multi-tasked learning was introduced so that a model can learn both spacing and POS tagging.
The Sejong Corpus has accurate spacing, sentence splitting, and POS information, so we used this corpus to train POS tag and spacing models. The two models share syllable based embedding and convolutions, but they have different fully connected layers. Each layer classifies spacing and assigns POS tags. We have trained these two models together with multi-task learning.
Loss is as written below. #58
- POS loss = cross entropy loss which evaluates POS by syllable
- Spacing loss = cross entropy loss which evaluates whether there will be a space after a syllable
- Total Loss = POS loss + spacing loss
Forward/backward steps are as written below.
- Don’t use embeddings of spacing syllable, forward, and calculate loss
- Use spacing syllables (with dropout applied), forward, and calculate loss
- Get total Loss and backward at once.
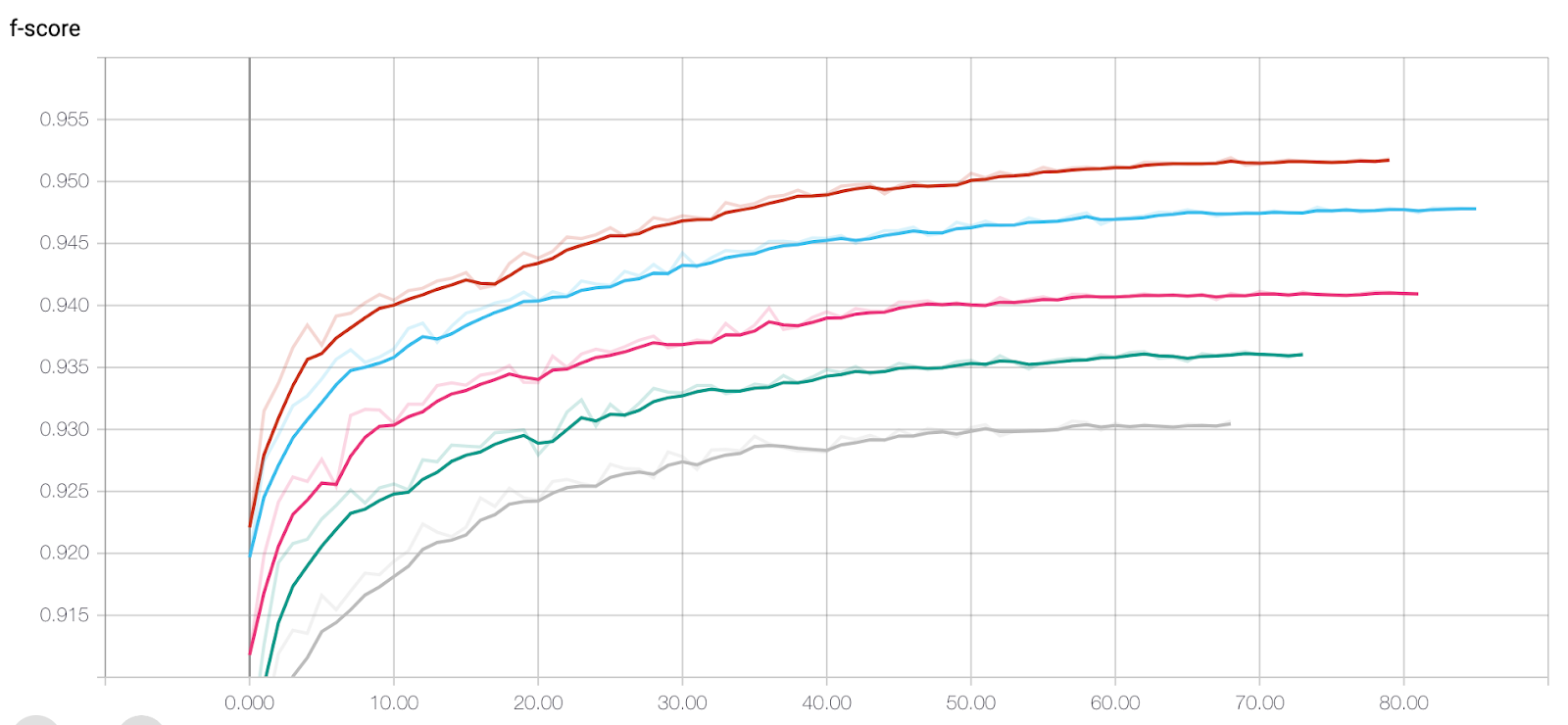
- Brown: existing single task learning
- Babyblue: multi-task learning (MTL)
- Pink: MTL dropout 0.25
- Green: MTL dropout 0.5
- Gray: MTL dropout 0.75
You will find a slight performance decrease in multi-task learning (baby blue), compared to single task learning (brown). If you compare MTL models with different dropout ratios, the performance decreases as the dropout ratio increases.
Does this mean the V0.3 model works the best? Let’s take a look at how the two models analyze the sentence, 아버지가 방에 들어가신다
| Model | Result |
|---|---|
| V0.3 | 아버지가방/NNG + 에/JKB + 들/VV + 어/EC + 가/VX + 시/EP + ㄴ다/EF + ./SF |
| MTL | 아버지/NNG + 가/JKS + 방/NNG + 에/JKB + 들어가/VV + 시/EP + ㄴ다/EF + ./SF |
We have looked through the models with dropout = 0.1 and an f-score of 95% and chosen the brown model with a window size of 4 and an embedding size of 35.

In order to compare the v0.3 and MTL models in a more quantitative way, we randomly deleted spacings in the test set and tested them as seen below.
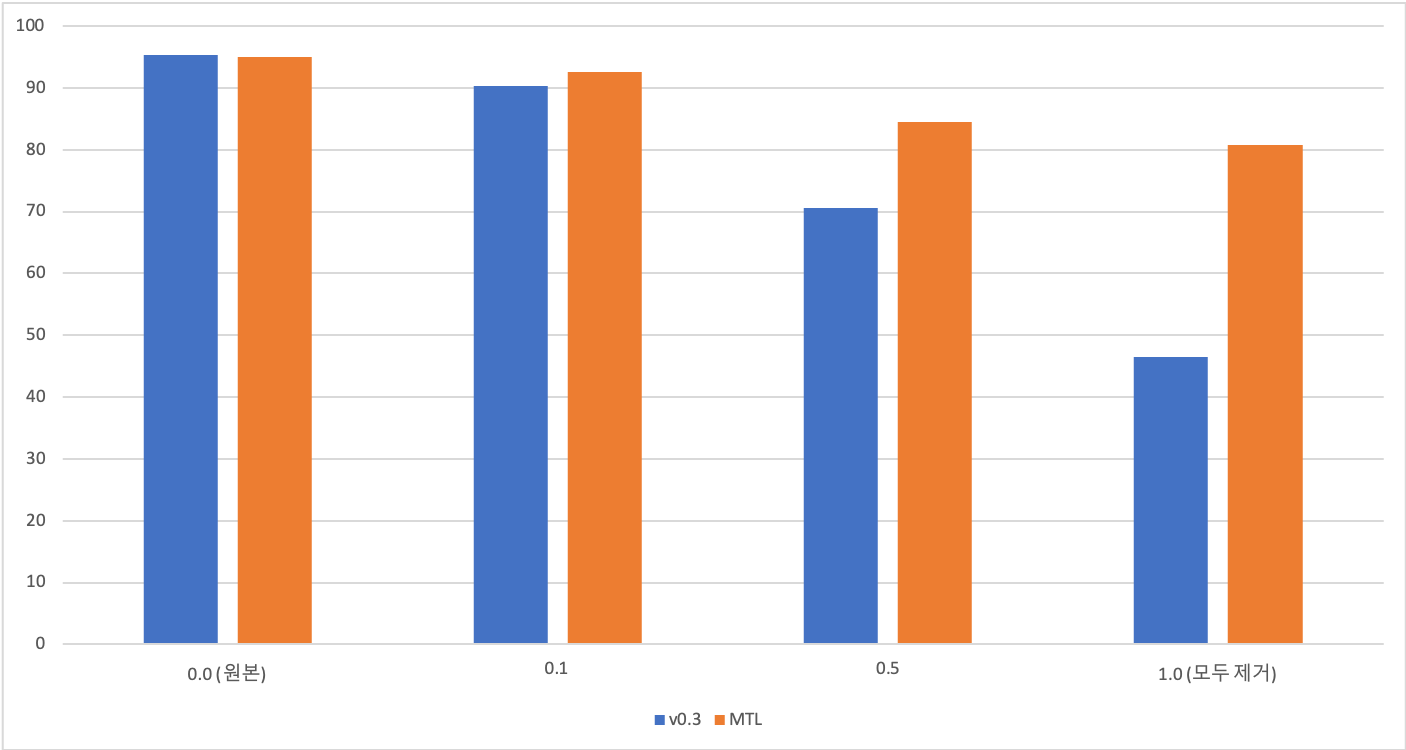
The v0.3 model’s performance drastically decreases as more spacing is deleted. On the other hand, the MTL model shows a moderately decreasing curve. When all the spacing is fully deleted, the MTL model has an accuracy of 80.76%, while the v0.3 model has an accuracy of 45.51%.
Conclusion
The multi-task learning model has a slightly lower performance than that of v0.3, but is strong at handling spacing errors. We can see that the v0.3 model is overfitted to the corpus which does not have spacing errors at all. As the Sebastian Ruder’s thesis also mentions, multi-task learning seems to be helpful in generalizing the model.
You can find translator's notes italicized
*The original document can be found https://github.com/kakao/khaiii. Please note that this document has not been reviewed by the Kakao team and it's just my personal project. Please feel free to provide feedbacks on any error that may occur during the translation process
Translator's Note
Introduce Khaiii Github Translation Project: Link
[Khaiii GIthub] Key terms & Concepts: Link
Other Khaiii Translation
[Khaiii Github] Read Me.md: Link
[Khaiii Github] Pre Analysis Dictionary: Link
[Khaiii Github] CNN Model: Link
[Khaiii Github] Test for Specialized Spacing Error Model: Link
[Khaiii Github] CNN Model Training Process: Link
[Khaiii Github]: Analysis Error Patch: [Link](
'Technical Writing > Khaiii Wiki Translation' 카테고리의 다른 글
| Khaiii Github - Analysis Error Patch (0) | 2021.07.16 |
|---|---|
| Khaiii Github - CNN Model Training Process (0) | 2021.07.14 |
| Khaiii Github - Key terms & Concepts (0) | 2021.07.12 |
| Khaiii Github - Pre Analysis Dictionary (Translated in Eng) (0) | 2021.06.24 |
| Khaiii Github - Read Me.md (Translated in Eng) (0) | 2021.06.24 |